
I am currently an undergraduate student in computer science at the University of Minnesota Twin Cities.
💻 Experience
- 2024.11 - 2025.10, Sun Yat-sen University, HCP Lab
- Research Focus: Multimodal Large Models, Embodied Instruction Following
- 2024.1 - 2025.3, Beijing University of Chemical Technology, Vision Lab
- Research Focus: Vision-Language Model, Noisy-Label Learning, Test-Time Adaptation
- 2023.9 - 2023.12, Beijing University of Chemical Technology, ACM Labå.
- Track: Data Structures / Graph Theory / Dynamic Programming — 📈 Contest rating: 1942.
🔥 News
- 2025.11: 🎉 FAST-CAD accepted as an Oral at AAAI 2026. Congrats to Tommy Sha!
- 2025.10: ✈️ Attended ICCV 2025.
- 2025.08: 📝 Submitted one paper on healthcare to AAAI 2026.
- 2025.06: 🎉 One paper accepted at ICCV 2025 on test-time adaptation.
- 2025.05: 📝 Submitted one paper about video understanding to NeurIPS 2025.
- 2025.03: 🎉 One paper accepted at ICME 2025 on test-time adaptation.
- 2025.03: 📝 Submitted one paper on test-time adaptation to ICCV 2025.
- 2025.03: 🎉 One paper accepted at ICLR 2025 FM-Wild Workshop on test-time adaptation.
- 2024.12: 📝 Submitted two papers to ICME 2025, one on test-time adaptation, the other on video understanding of action.
📝 Publications (* Equal Contribution)
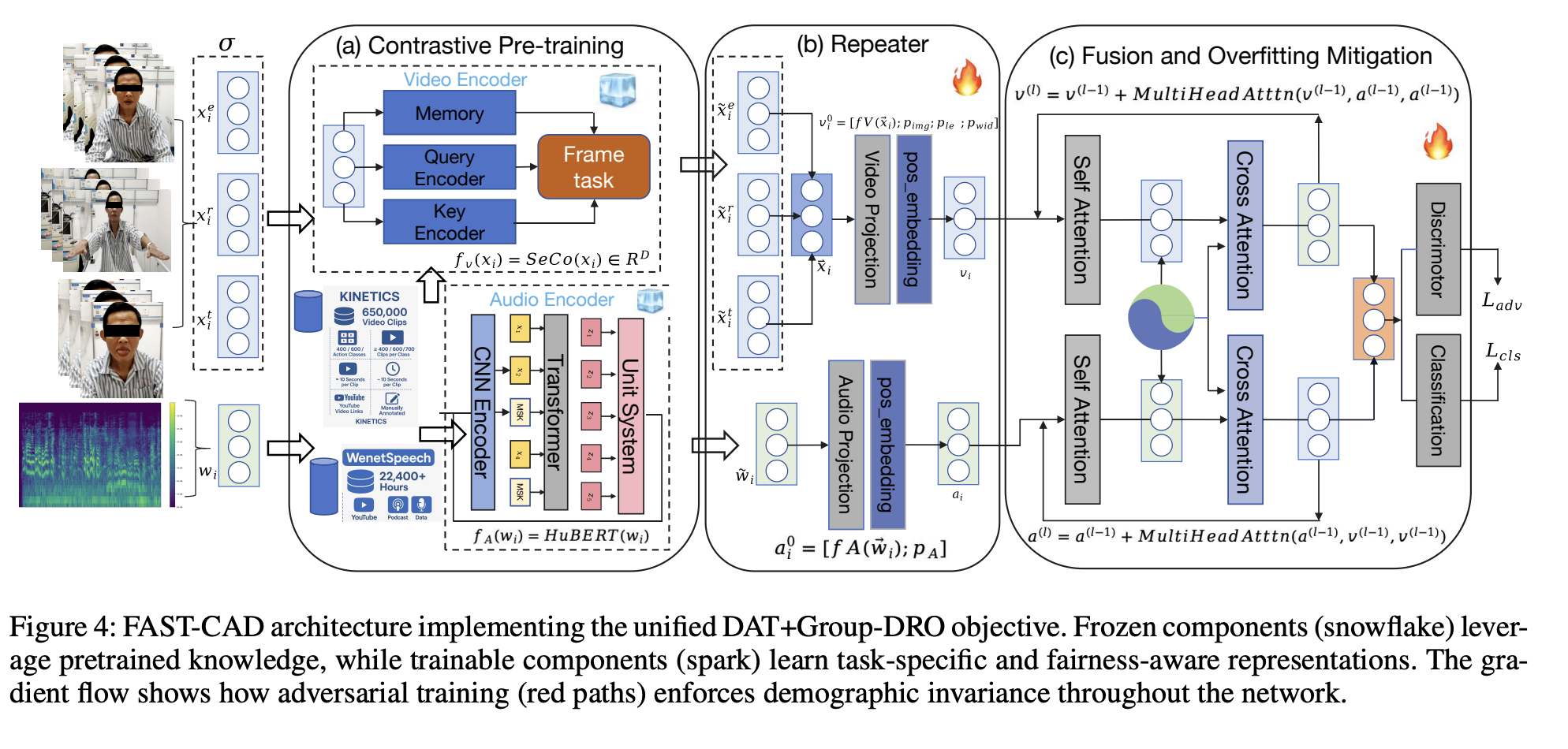
FAST-CAD: A Fairness-Aware Framework for Non-Contact Stroke Diagnosis
Project Page | MIT Tech Review
Stroke is an acute cerebrovascular disease, so we propose FAST-CAD, a DAT + Group-DRO framework that jointly enforces demographic-invariant representations and worst-group robustness for non-contact stroke diagnosis. Built on a 12-subgroup multimodal dataset, it couples adversarial domain discrimination with self-supervised encoders and optimizes worst-group risk, delivering 91.2% AUC and tight fairness bounds backed by domain adaptation and minimax theory.
Role: Collaborating Author.
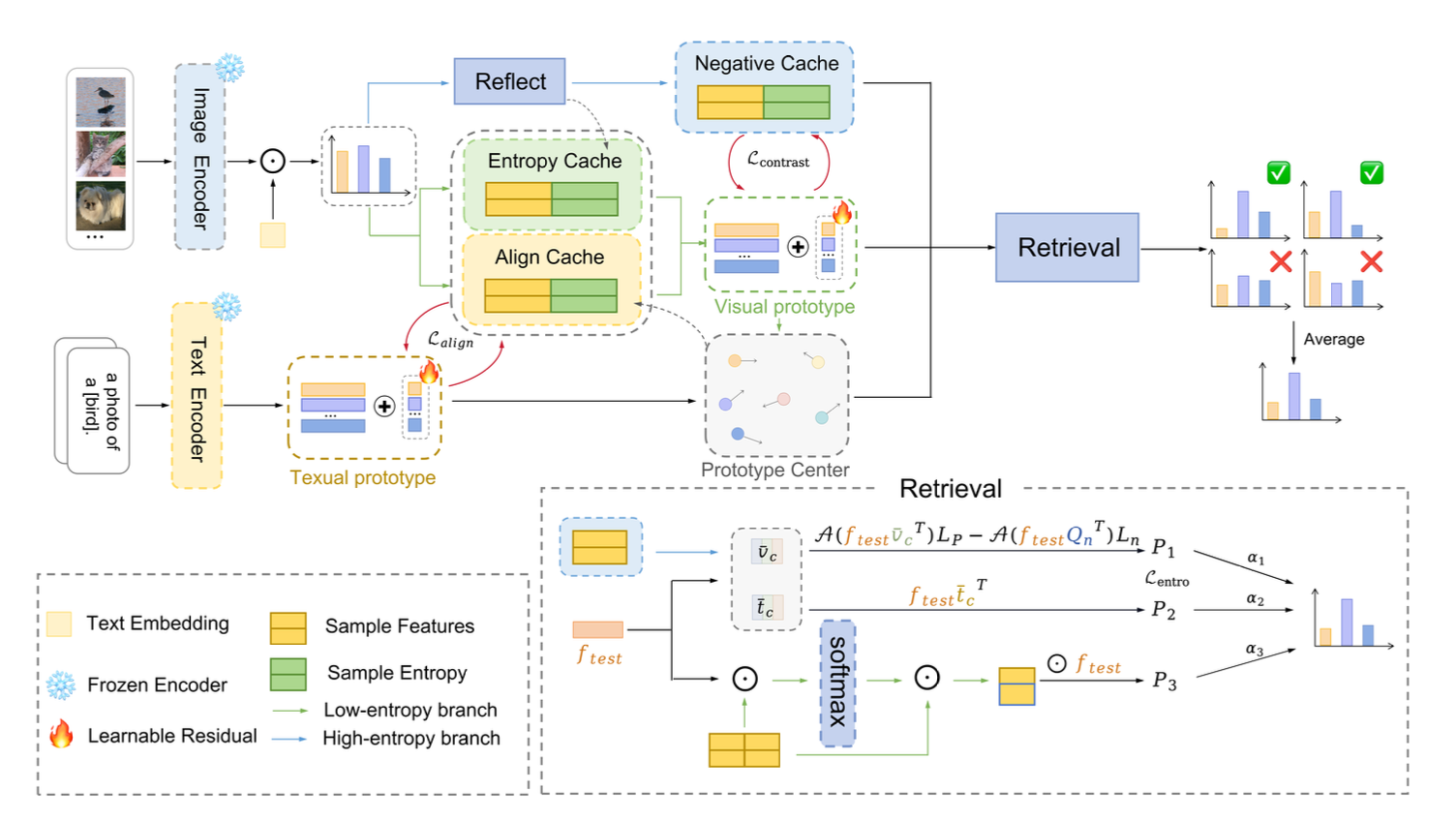
Multi-Cache enhanced Prototype Learning for Test-Time Generalization of Vision-Language Models
We observed that cache-based test-time adaptation performance is positively correlated with intra-class compactness. To address the unreliability of low-entropy samples under distribution shifts, we propose MCP, which uses an entropy cache for prototype initialization, an align cache to fuse visual and textual information and tighten intra-class distributions, and a negative cache to calibrate high-entropy predictions. We further extend this into the MCP++ framework by introducing cross-modal prototype alignment and residual learning, achieving state-of-the-art generalization on 15 downstream tasks.
Role: Co-first Author.
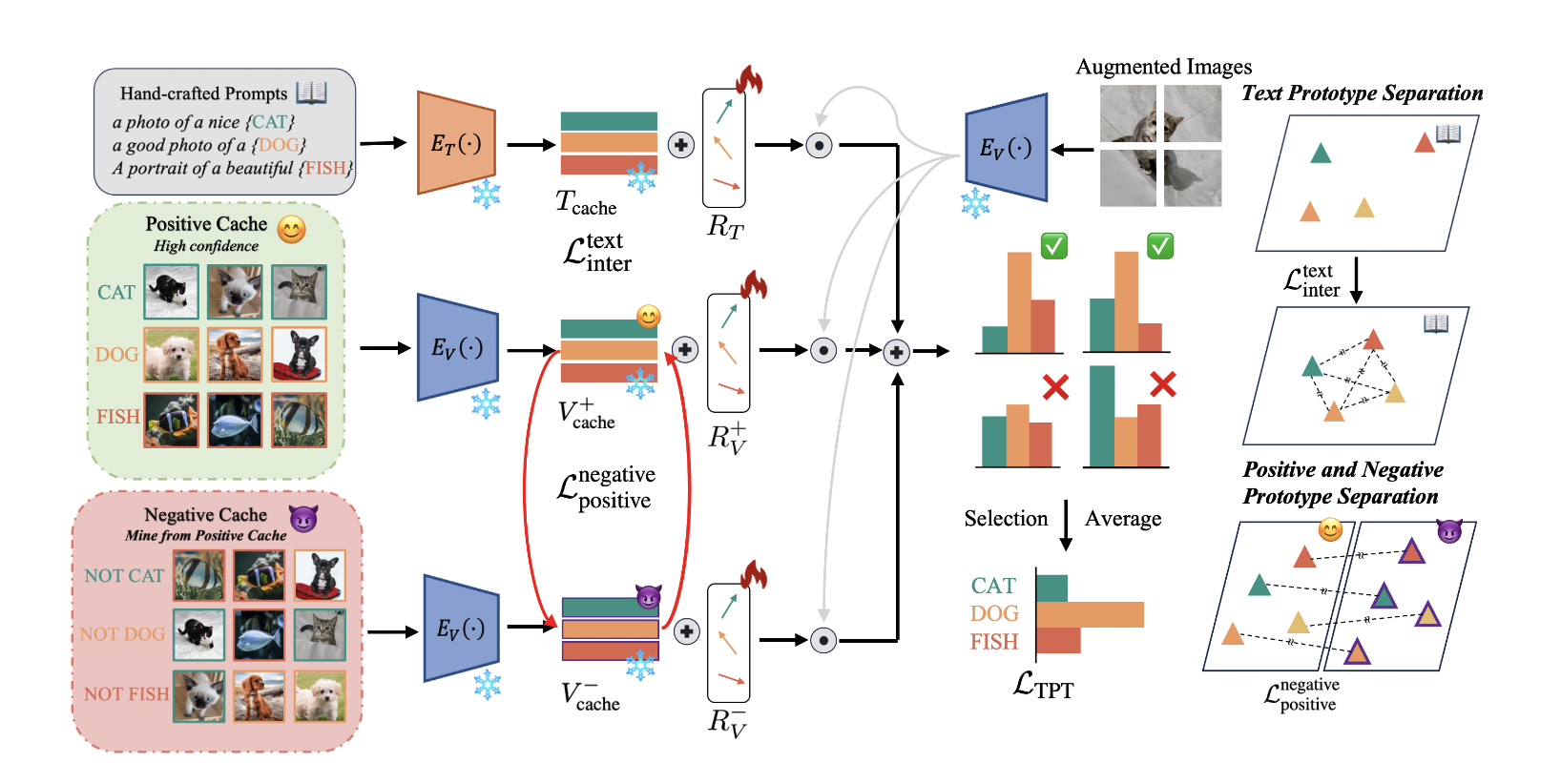
Mitigating Cache Noise in Test-Time Adaptation for Large Vision-Language Models
Also accepted at ICLR 2025 FM-Wild Workshop
We analyzed the root causes of the performance gap between zero-shot and few-shot TTA, identifying noisy cache labels as a critical bottleneck. We then propose the CRG framework, which maintains positive and negative visual prototypes alongside text prototypes, employs learnable residuals to align modalities, and leverages Gaussian Discriminant Analysis to dynamically model class distributions and suppress noisy samples. Finally, by jointly minimizing prediction entropy and maximizing inter-prototype distances, CRG achieves superior robustness and generalization across 13 benchmarks..
Role: First Author.
🔨 Project
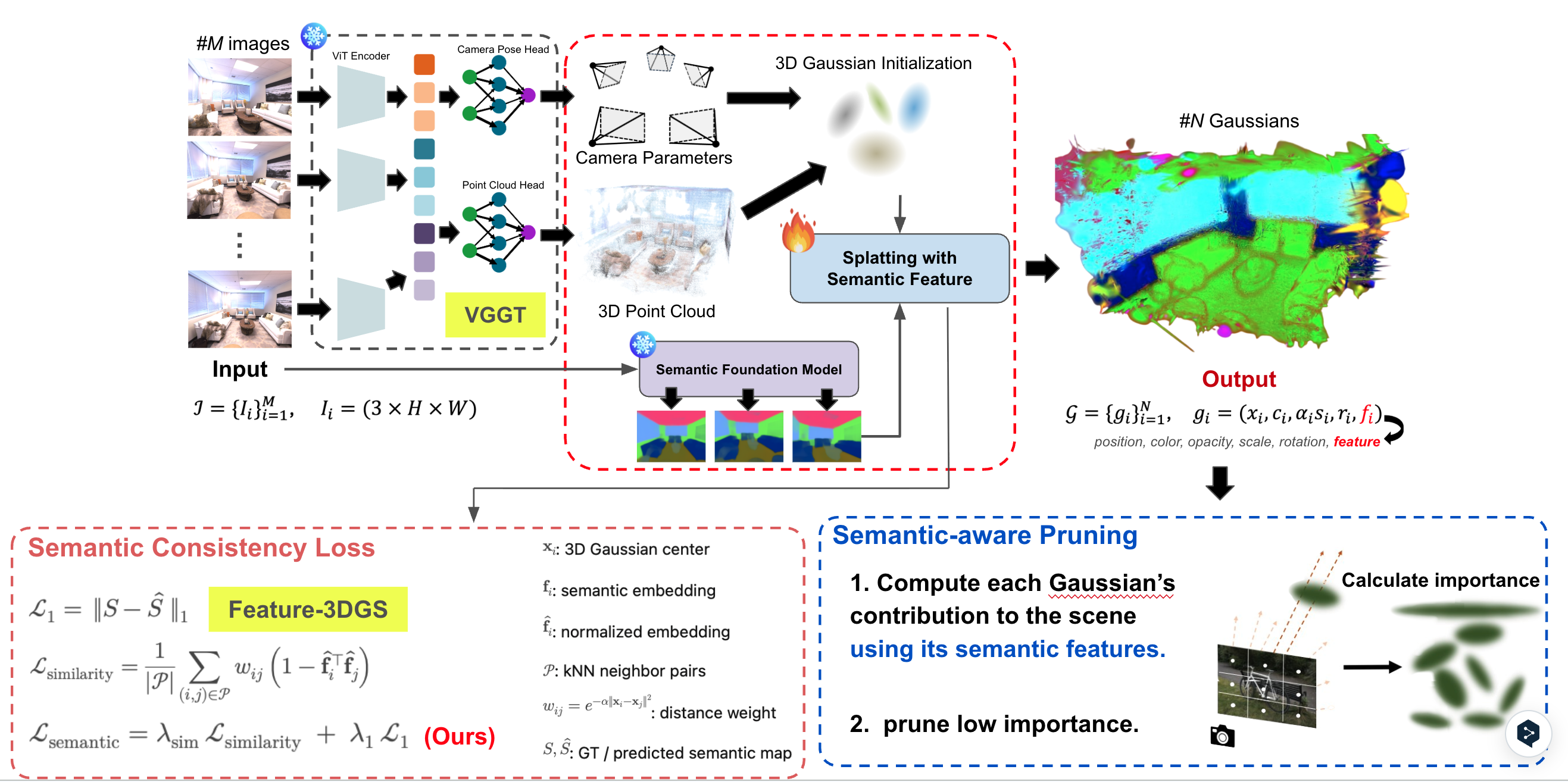
“Can We Make Feature-3DGS Faster, Better, and Smaller?”
We accelerate and shrink Feature-3DGS with semantic-aware Gaussian pruning and consistency loss, keeping fine details while boosting FPS and mIoU across Replica and Gopher/LindHall scenes.
- One Paper about Embodied Instruction Following and LLM Planning — TBA
- One paper about computer-use-agent — TBA
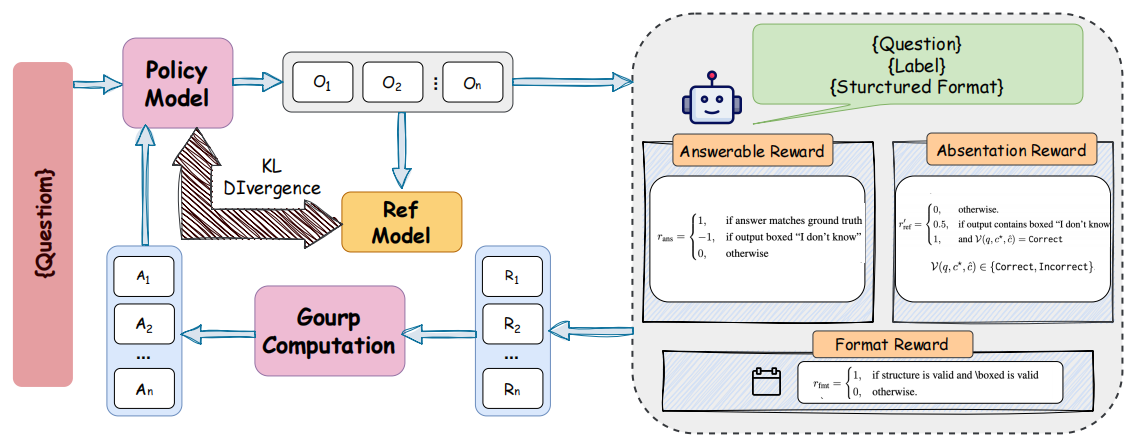
Abstain-R1: Absent Recognition and Calibration in Post-Training of LLMs
We propose Abstain-R1 that explicitly learns when to abstain on unanswerable queries and generates semantically meaningful post-refusal clarifications, improving refusal calibration while preserving strong performance on answerable prompts.
📨 Submissions
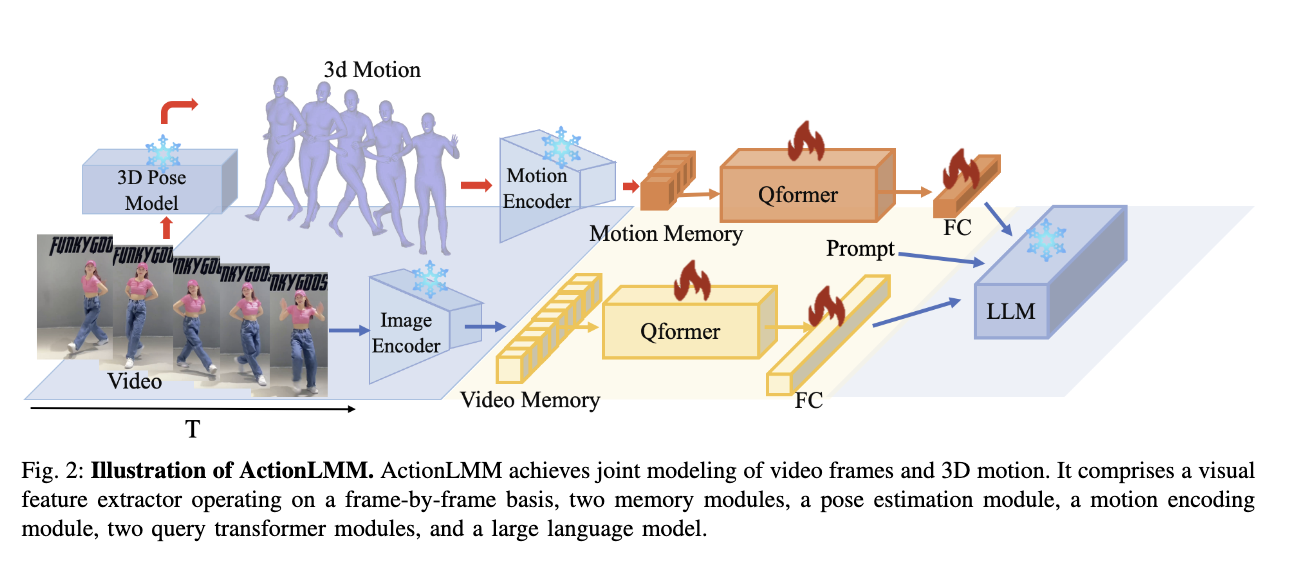
ActionLMM: A Large Multimodal Model for Detailed Action Description in Long Videos
We observe that existing video-language models (e.g., Video-LaMA, VideoChat) fail to capture fine-grained human actions because of data scarcity, modality misalignment, and the difficulty of modeling long clips. Introduces a dual-branch Q-Former that jointly learns from raw video frames and 3-D pose sequences, supported by video- and motion-memory banks, and trained on the new 30 k-video ActionCap-30k dataset. ActionLMM delivers fine-grained action captions and surpasses Video-LLaMA and other baselines on VQA, video captioning, and action captioning benchmarks.
- FASMM: Frame-Aware Sparse Multimodal Model for Scalable Long-Video Comprehension — Proposes Frame-Aware Sparse Attention (FASA) with an importance-driven block selector, cutting KV-cache memory by ≈ 8.8 × while retaining fidelity. FASMM processes tens-of-thousands-frame videos end-to-end and achieves state-of-the-art results on multiple long-video understanding tasks.
🎖 Honors and Awards
-
2025.05: 🎉🎉🎉 Selected for the Spring 2025 Dean’s List, University of Minnesota.
-
2023.10: 🎉🎉🎉 Achieved a silver (🥈) and a bronze (🥉) medal at the ICPC Asia Regional Contest.
📖 Educations
- present - 2027.6 (expected), Bachelor of Arts in Computer Science, University of Minnesota Twin Cities
🤝 Academic Service
- Conferences: Reviewer — ICME 2025/2026, AAAI 2026, ICASSP 2026
- Journals: Reviewer — IEEE Transactions on Industrial Informatics (TII)